
python基础
Numpy
创建数组
- 通过array()函数将Python的列表或者元组转换为数组
- 利用
zeros(), ones(), empty()函数创建 - 通过arange()函数得到数组,arange()函数的原型为
arange(start, end,step),起始值为start,终止值为end,但不含终止值,步长为step。arange()函数可以使用float型数据。
数组运算
元素对元素的乘法:a * b
矩阵的乘法:a @ b
形状改变
ravel()、reshape()、T这3个方法会返回已修改的矩阵,但不会更改原始矩阵
resize()方法会更改原始矩阵
pandas
Series
Series对象是Pandas中的一维数据结构,能存储不同类型的数据
a = pd.Series(["b", 2, [1 ,2]], index = ["a", "b", "c"])
DataFrame
DataFrame是Pandas中的二维数据结构,能存储不同类型的数据,有行索引和列索引,并与元素对应
1 | import pandas as pd |
表格文件操作
读取csv文件read_csv()
使用 to_csv() 方法将 DataFrame 存储为 csv 文件
表格数据处理:
head( n ) 方法用于读取前面的 n 行,如果不填参数n ,默认返回 5 行。
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
info() 方法返回表格的一些基本信息
1 | import pandas as pd |
Matplotlib
折线图 plot
散点图 scatter
柱形图 bar
多子图 subplot
直方图 hist
误差图 errorbar
图修饰
Scikit-learn
支持包括分类,回归,降维和聚类四大机器学习算法;还包括了特征提取,数据处理和模型评估三大模块
数据包
数据处理:from sklearn import datasets, preprocessing
数据集的划分:from sklearn.model_selection import train_test_split
建模的模型:from sklearn.linear_model import LinearRegression
模型的评估:from sklearn.metrics import r2_score
加载数据
Scikit-learn支持以NumPy的arrays对象、Pandas对象、SciPy的稀疏 矩阵及其他可转换为数值型arrays的数据结构作为其输入,前提是数据必须是数值型的
sklearn.datasets模块提供了一系列加载和获取著名数据集如鸢尾花、波士顿房价、Olivetti人脸、MNIST数据集等的工具,也包括了一些toy data如S型数据等的生成工具
eg:
1 | from sklearn.datasets import load_iris |
数据的划分
1 | from sklearn.model_selection import train_test_split |
将完整数据集的70%作为训练集,30%作为测试集,并使得测试集和训练集中各类别数据的比例与原始数据集比例一致(stratify分层策略),另外可通过设置shuffle=True
提前打乱数据
数据预处理
使用Scikit-learn进行数据标准化
- 导入
from sklearn.preprocessing import StandardScaler
\[ Z-Score标准化:x^*=\frac{x-\mu}{\sigma} \]
- 构建转换器实例
scaler = StandardScaler() - 拟合及转换
scaler.fit_transform(X_train)
监督学习算法-回归
LASSO linear_model.Lasso
Ridge linear_model.Ridge
ElasticNet linear_model.ElasticNet
回归树 tree.DecisionTreeRegressor
导入
from sklearn.linear_model import LinearRegression构建模型实例
lr = LinearRegression(normalize=True)normalize表示是否要进行归一化,即是否要将数据映射到[0,1]之间
训练模型
lr.fit(X_train, y_train),即进行拟合X_train表示训练集特征y_train训练集的目标值
作出预测
y_pred = lr.predict(X_test)X_test测试集的特征
监督学习算法-分类
逻辑回归:linear_model.LogisticRegression
支持向量机:svm.SVC
朴素贝叶斯:naive_bayes.GaussianNB
K近邻:neighbors.NearestNeighbors
导入
from sklearn.tree import DecisionTreeClassifier实例
clf = DecisionTreeClassifier(max_depth=5)拟合
clf.fit(X_train, y_train)预测
y_pred = clf.predict(X_test)y_prob = clf.predict_proba(X_test)
使用决策树分类算法解决二分类问题,y_prob为每个样本预测为“0”和“1”类的概率
监督学习算法-集成学习
sklearn.ensemble模块包含了一系列基于集成思想的分类、回归和离群值检测方法.
1 | from sklearn.ensemble import RandomForestClassifier |
无监督学习
sklearn.cluster模块包含了一系列无监督聚类算法.
DBSCAN:cluster.DBSCAN
层次聚类:cluster.AgglomerativeClustering
谱聚类:cluster.SpectralClustering
实例:
导入
from sklearn.cluster import KMeans构建聚类实例
kmeans = KMeans(n_clusters=3, random_state=0)拟合
kmeans.fit(X_train)预测
kmeans.predict(X_test)
评价指标
sklearn.metrics模块包含了一系列用于评价模型的评分函数、损失函数以及成对数据的距离度量函数.
回归模型评价

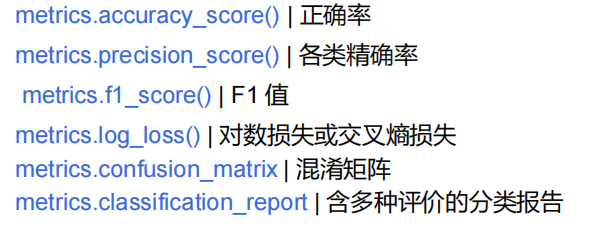
分类模型评价
交叉验证及超参数调优
超参数调优⸺网格搜索
在参数网格上进行穷举搜索,方法简单但是搜索速度慢(超参数较多时),且不容易找到参数空间中的局部最优
1 | from sklearn.model_selection import GridSearchCV |
超参数调优⸺随机搜索
在参数子空间中进行随机搜索,选取空间中的100个点进行建模(可从scipy.stats常见分布如正态分布norm、均匀分布uniform中随机采样得到),时间耗费较少,更容易找到局部最优
1 | from sklearn.model_selection import RandomizedSearchCV |





